Architecture
Two deployment modes
Managed
Majordomo operates Steward on its own infrastructure. You connect your cloud storage bucket, create an API key, and point your SDK at the gateway endpoint. No servers to run or maintain.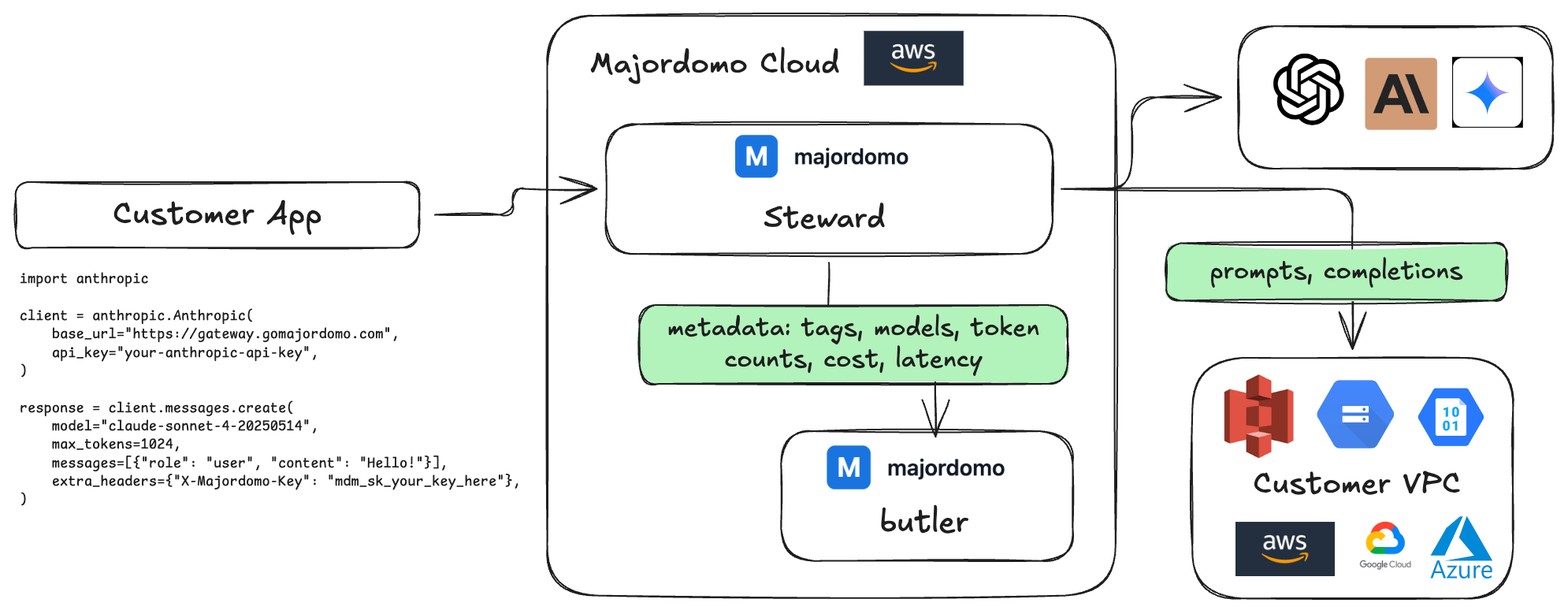
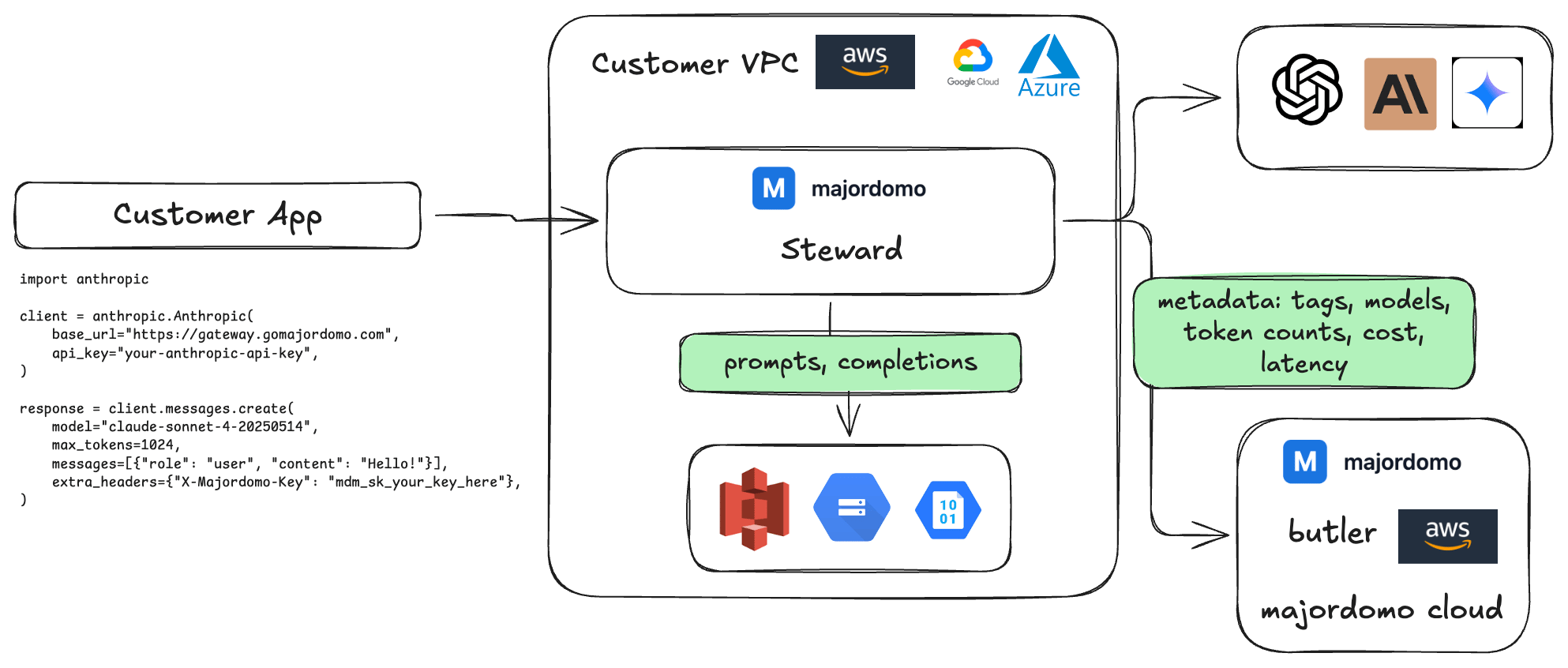
Self-hosted Steward (VPC)
You run Steward inside your own VPC. Your prompts and completions are processed entirely within your network — they never touch Majordomo’s infrastructure. Only metadata (token counts, cost, latency, model name) leaves your environment, sent to Majordomo Cloud to power the dashboard.Request flow
On every request, the gateway:- Validates the
X-Majordomo-Keyheader - Detects the provider from the request path or
X-Majordomo-Providerheader - Forwards the request to the upstream provider unchanged
- Parses the response for token usage
- Calculates cost using real-time pricing data
- Writes the request and response body to your S3 / GCS bucket
- Logs metadata to Majordomo asynchronously — no latency added to the critical path
- Returns the response to the caller — identical to calling the provider directly
What goes where
| Data | Destination | Who controls it |
|---|---|---|
| Prompt content | Your S3 / GCS bucket | You |
| Completion content | Your S3 / GCS bucket | You |
| Token counts | Majordomo Cloud | Majordomo |
| Cost | Majordomo Cloud (calculated locally, sent as a number) | Majordomo |
| Latency | Majordomo Cloud | Majordomo |
| Model name | Majordomo Cloud | Majordomo |
| Custom tags | Majordomo Cloud (only X-Majordomo-* headers you add) | You decide what to tag |
| Provider API keys | Your gateway database, encrypted at rest | You |
Provider detection
The gateway auto-detects the provider from the request path:| Path | Provider |
|---|---|
/v1/chat/completions | OpenAI |
/v1/messages | Anthropic |
/<model>:generateContent | Gemini |
X-Majordomo-Provider header when needed.